Terraform
Q) How to reference a module that is stored and released with a tag, in a specific repository in Github?
module "naming" {
source = "git::https://github.com/<ORG_NAME>/<REPO_NAME>.git//terraform/naming?ref=naming/v0.0.1"
}
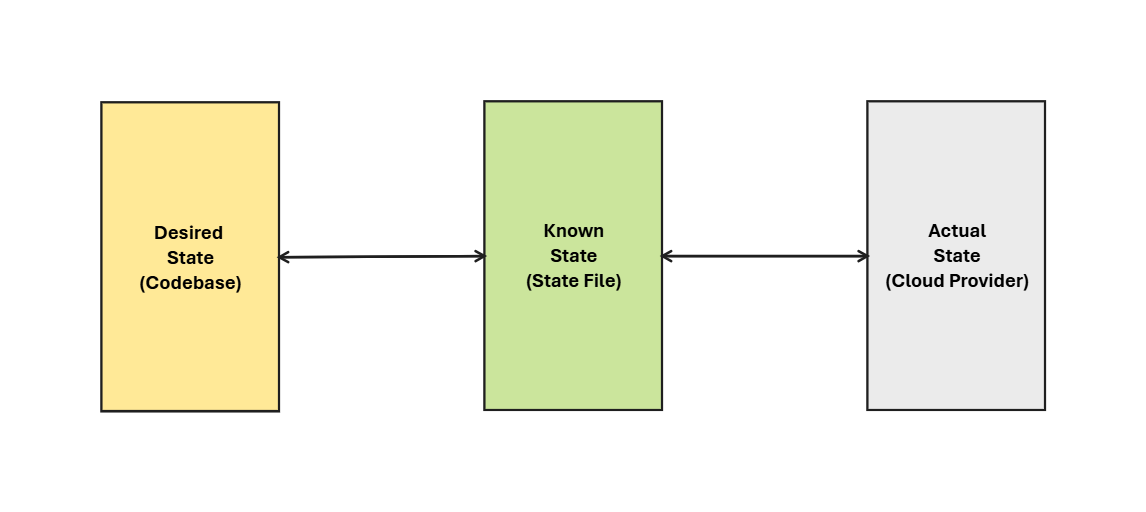
The Divine Trinity
terraform plan
TL:DR; What do I need to do to make Actual State match the Desired State?
- Check the desired state
- Check state file (address book) to find out which resources does Terraform manage, see their resource IDs (requires state lock)
- Run
terraform refreshto make a call to cloud provider API to check the status of resources in state file - Create an execution plan based on the delta between desired state and actual state for resources that are listed in state file
terraform apply
TL:DR; How do I execute the changes to force Actual State to match the Desired State?
- Run
terraform plan - Execute the plan
terraform destroy (terraform apply -destroy)
TL:DR; What do I need to do to remove the Actual State that is listed in the Known State?
- Run
terraform plan - Execute the plan
Notes:
- State lock must be acquired for any operation that reads or writes to state file.
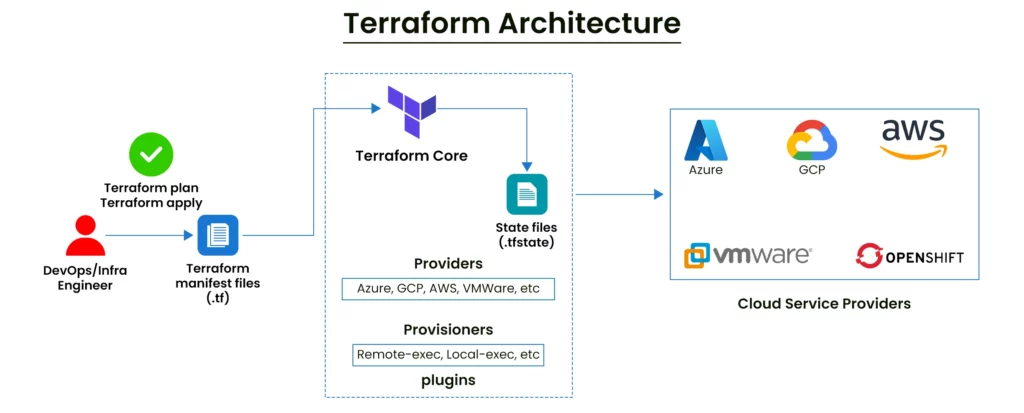
Q) What are the core components of Terraform?
Terraform has 2 main components.
Terraform Core is the CLI tool that we use to interact with Terraform. It takes two main inputs, and they are the existing state and the configuration (modules, main.tf, vars.tf and .tfvars files) that we want to make. It applies the difference between these two inputs.
Terraform Providers are the plugins that Terraform use in order to provision resources. Providers translate the desired configuration into the respective cloud’s REST APIs. For instance, if we want to create some resource on cloud using hcl, terraform basically converts the specifications into PUT request with defined parameters.
Q) How to simplify the concept of tfstate file?
Terraform asks itself: Which resources, am I responsible to manage? and to answer that question, it looks at the tfstate file. That’s all.
# Terraform variable values and provider binary downloaded after 'terraform init'
*.tfvars
.terraform*
# Terraform detailed execution plan binary after running 'terraform plan'
*.tfplan
# Terraform tfstate files (if local backend is used)
*.tfstate
*.tfstate.backup
Q) Which files should be added to .gitignore?
Add all .tfvars files that are inside of current directory into .gitignore. After we run terraform init, terraform also creates new folder named .terraform and executable binaries for provider, so we should also add them into .gitignore. .tfplan, .tfstate, .tfstate.backup files should also be stated in .gitignore.
# Initializes the Terraform workspace and backend and downloads all required providers that are stated in main.tf in root directory (let's begin command). It does not change the workspace or backend, so it can be run multiple times during build (I am done with the declarative files, let's roll) process.
terraform init
# Formats the files syntactically into canonical standard.
terraform fmt
# Validates all of the configurations and checks if there is anything wrong.
terraform validate
# This command runs a speculative plan on requested resources. It connects to cloud API to check the requested objects exist. It then shows the delta in the plan output that an admin can review and change the configuration if unsatisfied. Finally, it outputs the detailed execution plan into a file. It does not make any change in current infrastructure. It's a good practice to output the plan, since we know what will be applied when we run `apply` command.
terraform plan -var-file="./env/dev/terraform.tfvars" -out "rg_terraform_first.tfplan"
# Apply (literally do the operations which are defined in .tfplan file) to our infrastructure.
terraform apply "file_name rg_terraform_first.tfplan"
# When we use `terraform apply`, sometimes some of the resources are not getting created successfully, and terraform automatically taints them to recreate them in the next run. We can also manually taint resources to make them recreated again.
terraform taint <resource_name azurerm_resource_group.rg>
# In order to destroy the resources that we have deployed (they are stated in .tfstate file), we can run a speculative command to see which resources will be effected. Then, we are outputting the detailed execution plan, so that we have tangible file that expresses what will be done.
terraform plan -destroy -out <file_name rg_terraform_first_destroy.tfplan>
Q) How does modularity work in Terraform?
Terraform modules enable reusable, modular templates. For instance, if we define a module resource_group, this module will also have its own main.tf and vars.tf files. However, the exact values of these variables will be passed from vars.tf file during the initialization of this module in main.tf file in root directory. This part can be seen down below. It’s a good practice to modularize the hcl files as much as possible.
module "rg" {
source = "./modules/resource_group"
name = var.rg_name
location = var.rg_location
}
Q) Where to store state files?
Terraform uses .tfstate files in order to detect the current state of the infrastructure. Keeping them locally is not a good idea, since multiple people might want to configure existing infrastructure, and using git is not the best option. Because if we stage it to git repository, then it might be modified mistakenly, and thus that’s not the case we want to see. It should stay in where it will be protected, thus, we can use Azure Storage for this purpose.
Q) How does Terraform handles the differences between multiple environments?
Since we need multiple environments such dev, test, and prod in software development, we also need to separately create these environments, and they have to be identical. If we want do to something like this, the structure would become like:
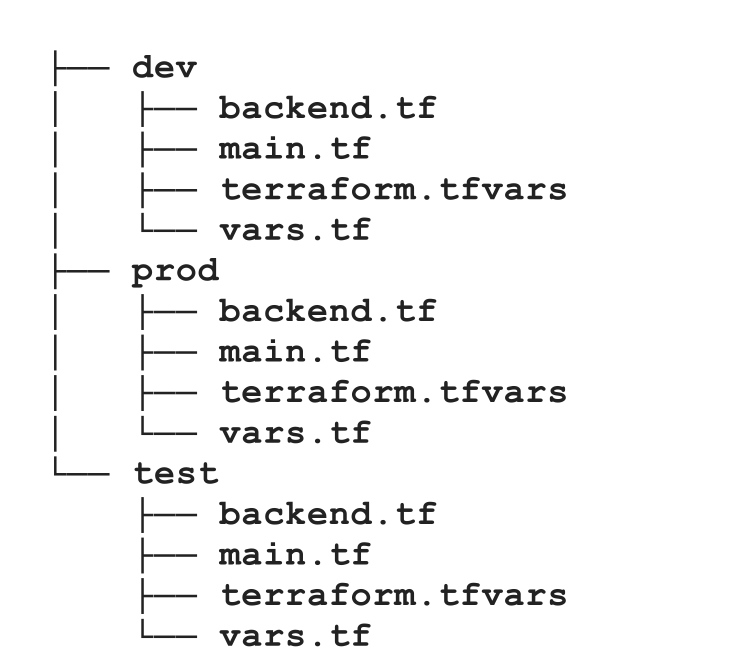
However, the duplication is there, and only change happens in terraform.tfvars files. That’s why we have workspaces in terraform. Terraform workspaces are nothing but independent state files. So we will have only one set of configuration files, and multiple state files. Thus, the final directory content becomes:

# Create new workspace.
terraform init
terraform workspace new <workspace_name>
# Switch to an existing workspace.
terraform workspace select <workspace_name>
Q) How to do resource naming properly, while working in multiple environments?
While we are defining resources, we can use the name of current workspace as follows:
resource "azurerm_resource_group" "main" {
name = "${var.rg_prefix}-${terraform.workspace}"
location = var.rg_location
}
Q) How does state file naming convention differ between local backend and remote backend?
If we are using local backend for .tfstate files, we would see the following structure of .tfstate files. However, in remote repositories, each .tfstate file is suffixed with env:<env_name>. So for instance, an example would be terraform-remote-backend.tfstateenv:dev

Q) What’s the benefit of using output in Terraform?
Terraform outputs, output specific values after the creation of the module or resource. For instance, we can output the name of a resource group to be able to specify which resource group the storage account or virtual network will be in. Following output.tf file exports name and the location of the resource group.
output "resource_group_name" {
value = azurerm_resource_group.rg.name
}
output "resource_group_location" {
value = azurerm_resource_group.rg.location
}
# To see all resources that terraform has created and manages.
terraform show
# To see the list of resources in .tfstate file.
terraform state list
# Remove a resource from the management of terraform. It does not remove the existing resource, terraform just stops managing it. Might be useful when someone manually deletes it from azure, and that is no longer needed.
terraform state rm <resource_name azurerm_virtual_machine.main>
# To import a resource that is created manually into terraform management, we can use `import` command.
az resource show --resource-group MyResourceGroup --name MyVM --resource-type \
Microsoft.Compute/virtualMachines --query id --output tsv
terraform import <resource azurerm_virtual_machine.main> <resource_id>
Q) What’s the benefit of using console in Terraform?
Terraform also provides a console to manage, investigate resources.

Q) How does Terraform handle dependencies between resources?
Terraform uses a dependency model to manage in what order resources are created and destroyed. There are two kinds of dependencies – implicit and explicit. We’ve been using implicit dependencies until now, where the VM depended upon the network interface, and the network interface depended upon the subnet. The subnet depended upon the virtual network, and all of these resources depended on the resource group. These dependencies naturally occur when we use one resource’s output as another’s input. It is possible to use depends_on attribute if we want to explicitly state dependencies. However, Terraform uses parallelism, that’s why using depends_on attribute might slow down the apply process.
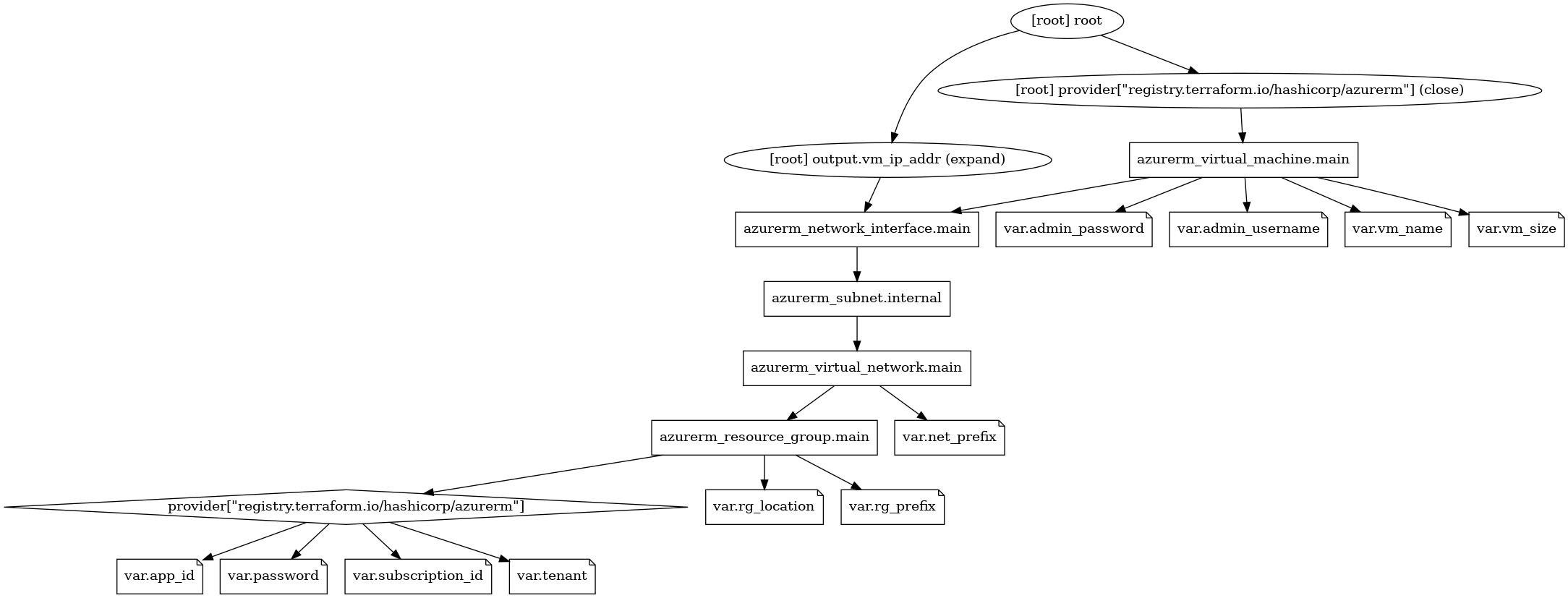
Q) Is it possible to visualize the terraform configurations in hierarchical order?
# To visualize the terraform configurations in hierarchical order. Example diagram can be seen below.
terraform graph > graph.dot
sudo apt install graphviz -y
cat graph.dot | dot -T png -o graph.png
Q) Can we use variables from vars.tf file in backend configuration?
For backend config, using variables from vars file is not allowed. It needs to be explicitly stated.
terraform {
backend "gcs" {
#bucket = "tf-state-mdo-terraform-${var.project_id}"
prefix = "sba-terraform"
#prefix = var.prefix is not allowed
}
}
Q) When to use locals or outputs?
- Use Locals for Readability: If an attribute is used multiple times or if naming it can make the code clearer, consider using a
localvariable. This keeps your code clean while improving readability. - Use Outputs in Modules: If you are writing modules, always expose important attributes through
outputblocks so they can be easily consumed by other modules or configurations.
Q) How does setting subscription_id under provider block affect the scope of the deployment?
The provider uses this priority order:
- Provider block explicit settings (subscription_id, client_id, etc.)
- Environment variables (ARM_SUBSCRIPTION_ID, ARM_CLIENT_ID, etc.)
- Azure CLI authentication (from az login and az account set)
So even if az cli uses another subscription, the value that was set under provider section will be used for the scope of the deployment.
Q) Why do we have features {} under provider block?
It’s used for optional feature flags, such as:
provider "azurerm" {
features {
# Resource Group
resource_group {
prevent_deletion_if_contains_resources = true
}
# Virtual Machine
virtual_machine {
delete_os_disk_on_deletion = true
graceful_shutdown = false
skip_shutdown_and_force_delete = false
}
# Key Vault
key_vault {
purge_soft_delete_on_destroy = true
purge_soft_deleted_keys_on_destroy = true
purge_soft_deleted_secrets_on_destroy = true
purge_soft_deleted_certificates_on_destroy = true
recover_soft_deleted_key_vaults = true
recover_soft_deleted_keys = true
recover_soft_deleted_secrets = true
recover_soft_deleted_certificates = true
}
}
}
If nothing is provided, then the default settings will apply.
Q) How does the versioning work in Terraform, for both of its CLI and providers section? What’s the benefit of using ~> operator?
It’s called as pessimistic constraint operator - it assumes that any major changes would break something in the deployment. It is only allowed to change the last field of the version, with this operator. Examples are:
~> 1.14.0
✅ Allows: 1.14.0, 1.14.1, 1.14.2, 1.14.3, ... 1.14.999
❌ Blocks: 1.15.0, 1.15.1, 1.16.0, 2.0.0
~> 1.14
✅ Allows: 1.14.0, 1.15.0, 1.16.0, 1.99.0 (any 1.x after 1.14)
❌ Blocks: 2.0.0
Q) Is it possible to deploy resources into different subscriptions, within a single codebase?
Yes - by defining multiple providers block and setting alias for them would allow us to have a single codebase that is responsible with deployments across subscriptions. Following example shows how to use different providers for different modules:
# Default provider
provider "azapi" {
subscription_id = var.subscription_id
}
# Production subscription provider
provider "azapi" {
alias = "prod"
subscription_id = var.prod_subscription_id
}
# Dev subscription provider
provider "azapi" {
alias = "dev"
subscription_id = var.dev_subscription_id
}
# Module using default provider
module "subnets_default" {
for_each = var.subnets_default
source = "../../"
# Uses default azapi provider automatically
// ...existing code...
}
# Module using prod provider
module "subnets_prod" {
for_each = var.subnets_prod
source = "../../"
providers = {
azapi = azapi.prod
}
// ...existing code...
}
# Module using dev provider
module "subnets_dev" {
for_each = var.subnets_dev
source = "../../"
providers = {
azapi = azapi.dev
}
// ...existing code...
}